
August 12, 2025
Shining light on the “dark corners” of API integrations
Jeff Carr
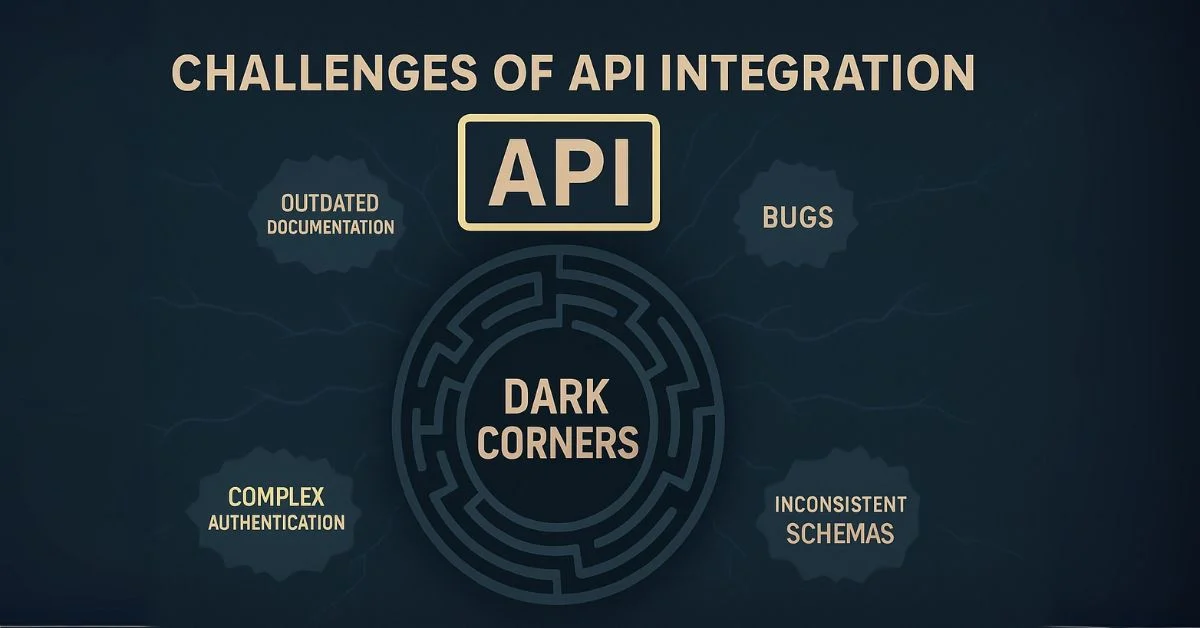
Back in June, Precog was a sponsor at the annual Snowflake Summit in San Francisco, an event filled with insightful content and productive meetings. A session led by Artin Avanes, Senior Director of Product Management at Snowflake, particularly resonated with us. He highlighted the challenges of data integration, especially regarding API integrations, noting a peer's comment that "API integrations are the most difficult due to all the dark corners various APIs have." As a company dedicated to solving this problem, this statement struck a chord.
Why “dark corners” persist
What exactly are these "dark corners"? They are numerous, but some common examples include outdated API documentation, which developers rarely update as changes are made. Many APIs also deviate from standard specifications, and bugs can persist for years. We recently encountered a significant bug in a major application used by most large companies, which affected returned data for an extended period. Beyond bugs and poor documentation, challenges also arise from complex authentication flows, intricate data models, or even simple user customizations within applications. These issues significantly impede developers from building API integrations. For instance, developers coding to a "standard" schema documented for custom fields will be unaware of them, leading to their omission until the connector code is modified. These "dark corners" persist due to a lack of innovation and willingness to solve these problems. Instead, mainstream vendors and large company data engineering teams often resort to throwing more developers and coding at the issue, leading to exploding technical debt and perpetuating the problem.
Addressing the problem at scale
At Precog, our initial goal was to innovate and create scalable solutions for these "dark corners" of API integrations. We have successfully addressed these issues, ensuring that "dark corners" don't hinder our progress. This is why we provide significantly more Application API integrations into Snowflake than any other vendor—a fact, not aspiration or hyperbole. So, how did we achieve this? Let me walk you through our innovations.
When considering a new API integration for ELT purposes, the problem boils down to two main issues. First, you need to connect to the API, make requests, and receive responses. This includes managing things like pagination, rate limits, token refreshes, and complex authentication flows, just to name a few of the challenges. Generative AI proves useful here, but only if you avoid general-purpose programming languages, which create too large a surface area for efficient training data set creation. At Precog, a user simply inputs the API documentation, and our platform generates a concise configuration file. This file provides all necessary instructions to connect, maintain the connection, make requests, retrieve data, and continuously update data as it changes in the source (CDC or incremental loading). This first step, while crucial, is the easiest part, as we have constrained the problem space for speed and efficiency.
The second, and most difficult, part of the problem involves the API responding with numerous datasets, sometimes thousands, all in object format (most commonly JSON, but also XML, CSV, and others). Regardless of the format, these object schemas must be transformed into a usable SQL schema before being loaded into Snowflake. By "usable," I mean a fully normalized schema with fully typed data and primary keys for all tables—essentially, something that any common BI or ML tool can immediately utilize. Furthermore, due to the custom fields mentioned earlier, a "prebuilt" schema transformation based on documentation would almost certainly be incorrect, as it wouldn't account for any custom fields. Our approach to this problem is simple: since Precog doesn't need to "prebuild" any schema deconstruction, we simply interrogate the API response to determine the data present and the specific structure or schema of each and every object. This provides us with a complete map of all the data and its structure.
Precog’s breakthrough innovation
The next step is our major innovation at Precog: our "evaluator" processes the "staged or raw" interrogated data in a streaming manner, emitting rows as the data or object is evaluated. This process is incredibly fast and handles any object size or level of complexity, without exception. It doesn't rely on concepts like sampling, which is proven to not work with large heterogeneous objects. Our testing datasets include individual objects over 50GB with extensive levels of nesting and other complex object schema attributes.
To reiterate, we accept object data from an API request, interrogate it during the staging process to understand its structure and content, then emit a SQL schema in a streaming fashion. This entirely novel approach, combined with our other innovations, allows Precog to create completely new API integrations in hours, without a single line of code. They simply work. A user can input the required information into our system, and within hours, a completely business-ready SQL schema for any API in the world will be loading into Snowflake. This is how we eliminate the "dark corners." And with our highly focused training data that is constrained to the problem, the platform continuously learns and improves at creating new integrations.
A natural benefit of this approach is that these connections are much simpler to maintain, requiring less human effort and time. The result is more data into Snowflake, faster, simpler, and without delays. Just as other AI technologies like ChatGPT and Snowflake Cortex have revolutionized insight, data access, and time-to-value across data, Precog's approach and innovation are transforming the future of API integrations and eliminating all those "dark corners."
The new status quo
Users who continue to manually build integrations in Python or other programming languages, or rely on complex workflow builders that demand significant effort for creation and maintenance, simply will not be competitive in the market going forward.
Applying AI and Machine Intelligence is the ONLY way to solve this challenge once and for all. Continuing to waste millions of hours and dollars on tedious manual builds, when AI can accomplish the same in hours, is a waste that must cease. Changing the status quo is never easy, and if your job is hand-coding these sorts of connectors, you probably prefer to keep doing it that way, but in the end, innovation always wins, and the new status quo will be Precog, soon enough.
Of course, the easiest way to learn the power of the Precog approach to API integration is to try it out. Need an API integration for Snowflake that you can't find? Let Precog create it, in hours.
Happy integrating!


.svg)


